▋ 前言
AOI(自動光學檢測)扮演了全線自動化重要的角色,原因是整個自動化生產中,光學檢測屬於最難自動化的一部分,光學檢測涵蓋了自動化工程、資訊整合、光路設計及檢測演算法設計。如圖一所示每項技術都要完成才能建置起AOI系統。

圖一、AOI系統
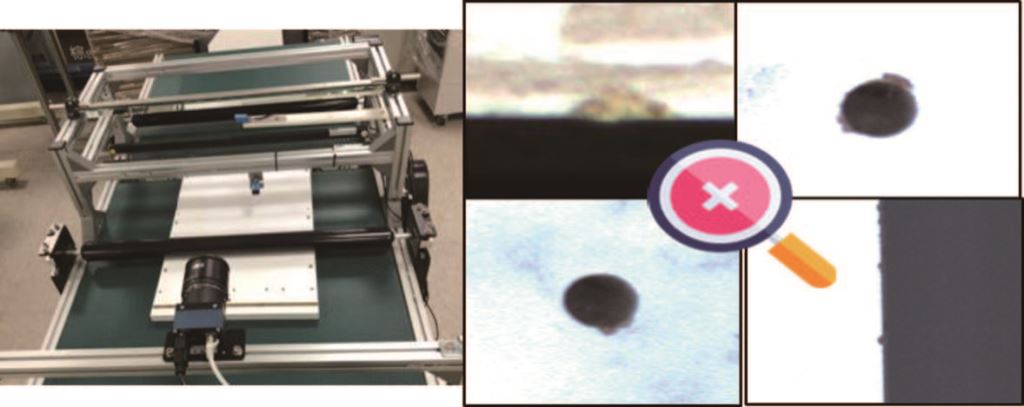
AOI系統中,檢測演算法設計是一道主要的難題,成千上萬種的演算法僅能靠著工程師的經驗進行嘗試,開發時間相當可觀,且對於複雜紋理特性的待測物與多變的瑕疵型態常會發生漏檢或過檢的狀況如圖二所示,以至於不易導入AOI。
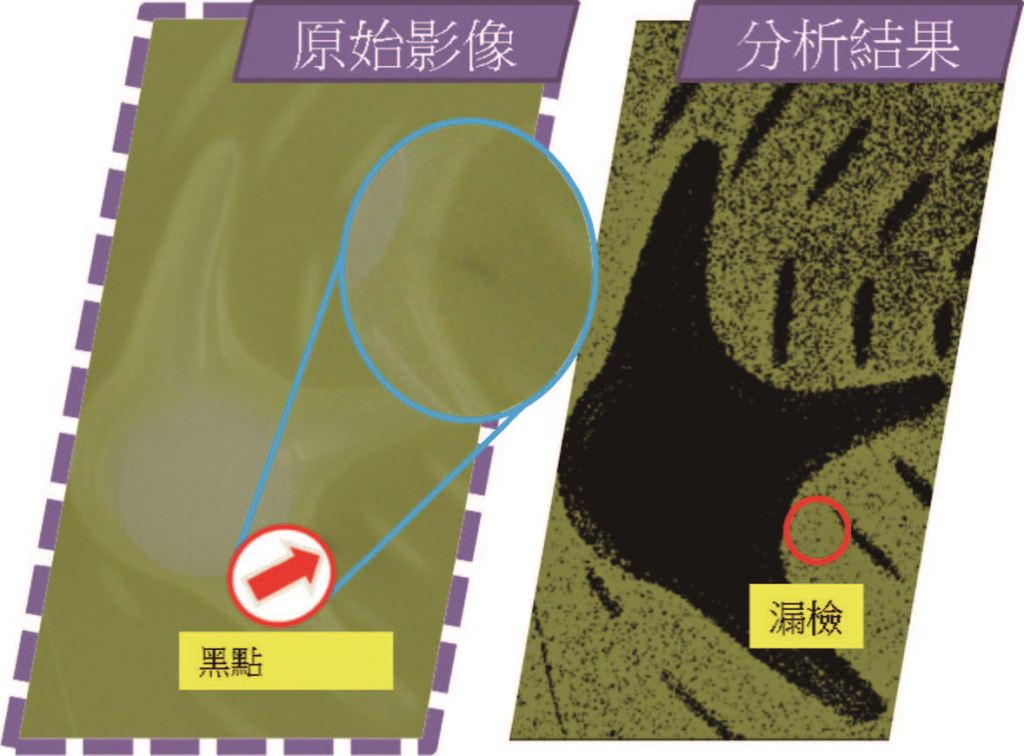
圖二、待測物上的黑點瑕疵漏檢
受限於人為設計的檢測演算法極限所在,因此目前現場主要還是仰仗人工目視檢測如圖三所示,但又面臨每個人主觀意識認定的不同,品檢跟不上生產速度,加上品檢員也會隨著工作時間增加產生疲勞的問題容易出錯,更別提當有經驗的品檢員離開後,新人要上手需要一段時間,這空窗期對於工廠是刻不容緩的。

圖三、人工目視檢測
近年來,AI卷積神經網路(Convolutional Neural Network)的技術進步速度突飛猛進,讓AOI看到了新希望,卷積神經網路仿造人類的視覺系統及大腦認知方式,例如人類在辨識一個目標物時,會先注意到特徵明顯的地方,可能是鮮明顏色的點、線、面或者是獨特的特徵眼睛、鼻子、嘴巴,這些抽象化的過程就是卷積神經網路演算法所做的事情,架構如圖四所示。
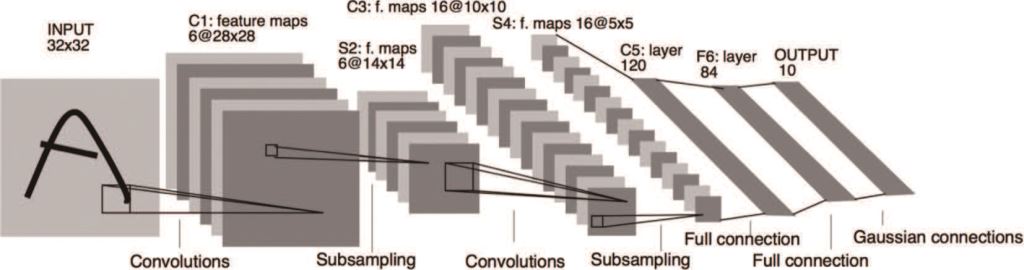
圖四、卷機神經網路架構[註1]
透過卷積神經網路自行學習像素級別的特徵,能做到瑕疵分類、定位,甚至分割,克服人為設計的檢測演算法之限制,差異如圖五所示,且對於複雜紋理的待測物也能進行瑕疵檢測。卷積神經網路能根據獲取的影像當作訓練資料,以不斷提升模型強度,若要新增瑕疵也僅需要蒐集影像資料並訓練模型,無須再重新開發演算法,省去了重新開發的時間耗費,卷積神經網路的導入將讓整個產業全面升級,以AI AOI推向自動化及智慧化的生產工廠。
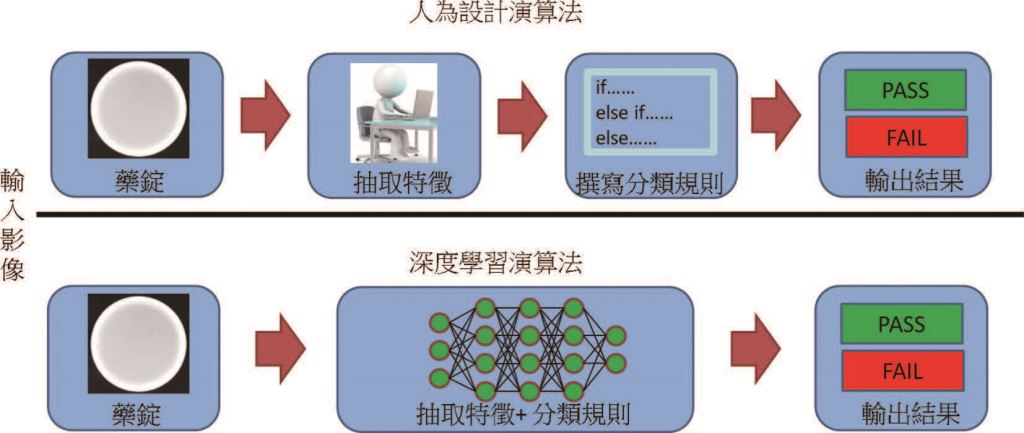
圖五、人為設計演算法與深度學習演算法之差異
▋ 卷積神經網路技術
目前卷積神經網路技術主要分為影像分類(Image Classification)、物件偵測(Object Detection)、語義分割(Semantic Segmentation)及實例分割(Instance Segmentation),四種任務涵蓋了AOI常用的使用情境如圖六所示,其中各個技術架構些微不同,應用場合也不同,以下將各項技術進行說明:

圖六、卷積神經網路技術種類
(1) 影像分類
影像分類技術是用來判斷此張影像屬於哪一個類別,但無法提供目標物定位及輪廓資訊,主要應用於影像擁有明確的一種類別答案,像是水果選別機判斷A、B等級或破損藥錠快速檢測等,由於影像分類技術為卷積神經網路中訓練速度及運算速度最快,又為最基礎的,因此許多教學及演練大都以影像分類技術為主,有名的影像分類演算法如VGG[註2]、ResNet[註3]、EfficientNet[註4]皆是眾所皆知的,影像分類架構示意圖如圖七所示。
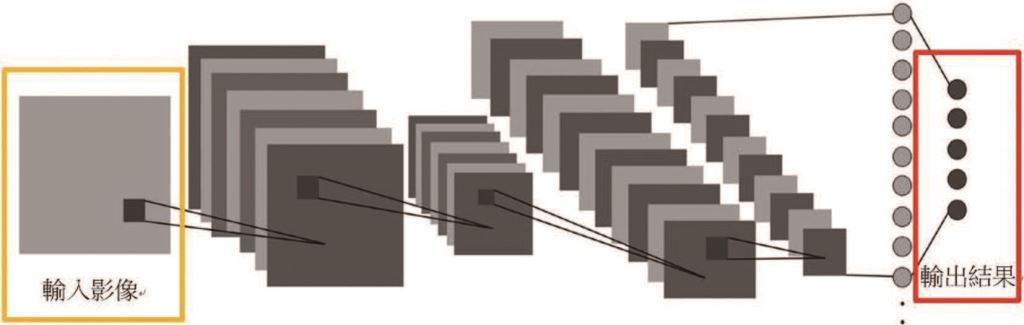
圖七、影像分類架構示意圖
另外,影像分類技術中變形之良品分類技術也常受到矚目,由於現今的影像分類技術大多需要有相當的不良品才能進行學習,但實際產線通常有著高生產品質之特性,蒐集不良品資料相當不易,而良品分類任務的思想則是僅學習大量的良品來觀察良品應有的特徵,當有不良品影像時,即能判斷出與良品特徵不同,進而檢出不良品如圖八所示,良品分類技術更接近現場實際應用的情境。
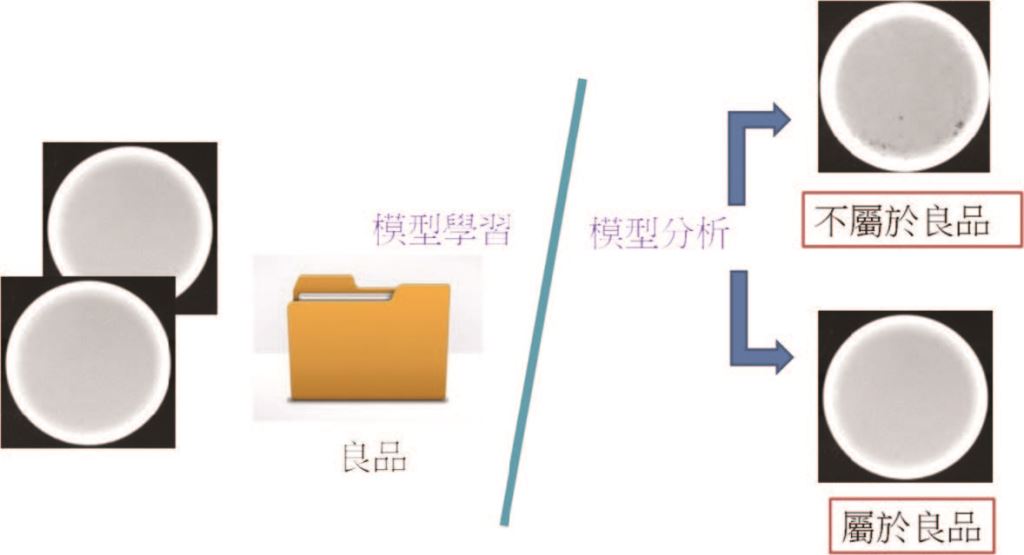
圖八、良品分類情境圖
(2) 物件偵測
用於判斷此張影像哪些地方有目標物,物件偵測技術可提供出目標物的位置及目標物的類別,可應用於瓶罐瑕疵檢測、木板異常紋理檢測等。物件偵測技術是由影像分類技術為基礎延伸出能夠定位的演算法,定位出的目標物會以方框進行標示,不會描繪目標物輪廓,好處是運算速度僅慢於影像分類技術,又可帶出目標物位置資訊。有名的物件偵測演算法YOLO已經從2015年[註5]第一代進化到2022年第七代[註6],檢測速度、學習速度、影像分類能力及定位 方框精度皆不斷強化如圖九所示,名聲近乎無人不知,只要是物件偵測的需求,第一個就會想到YOLO。
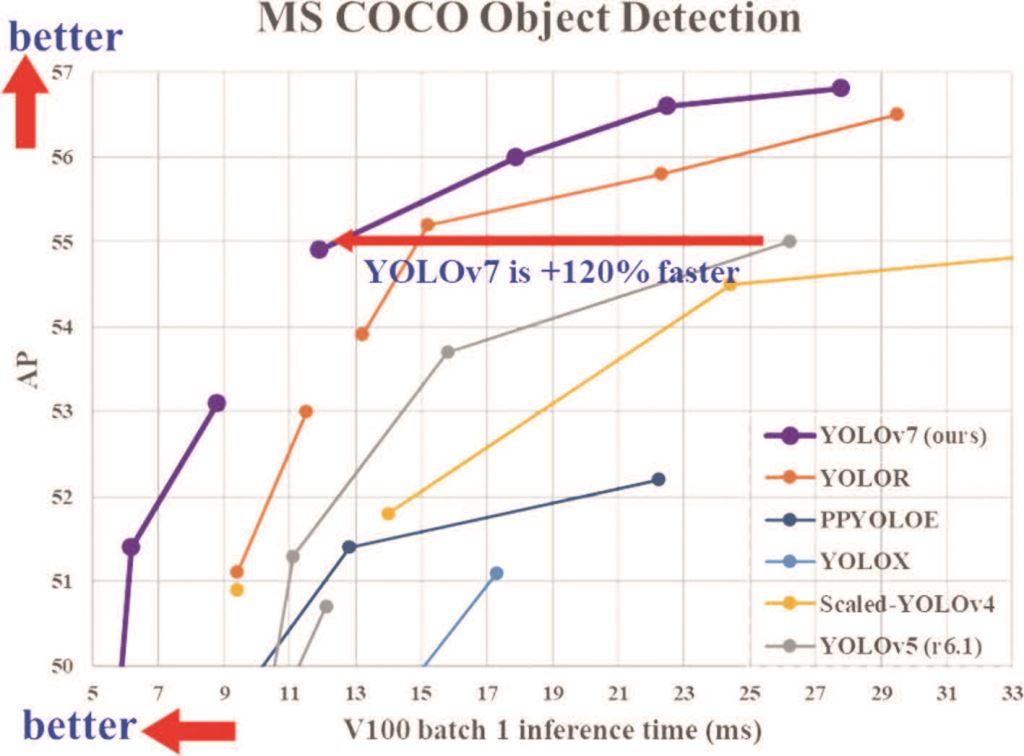
圖九、YOLOv7性能比前幾代更準更快
(3) 語義分割
語義分割技術是將影像以像素級別來做分析,針對每一個像素進行分類,看似與物件偵測技術相同,皆是影像分類及定位,但不同的是不只能夠定位,還能描繪出目標物輪廓,可應用於有嚴格訂定檢查規則之瓶罐檢測(例如面積大於0.5mm2的黑點須視為NG,反之視為OK)。雖然語義分割技術相較於物件偵測技術與影像分類技術運算速度慢,但能以提供出輪廓及面積更詳細的資訊,有名的演算法如Unet[註7],Unet架構如圖十所示。
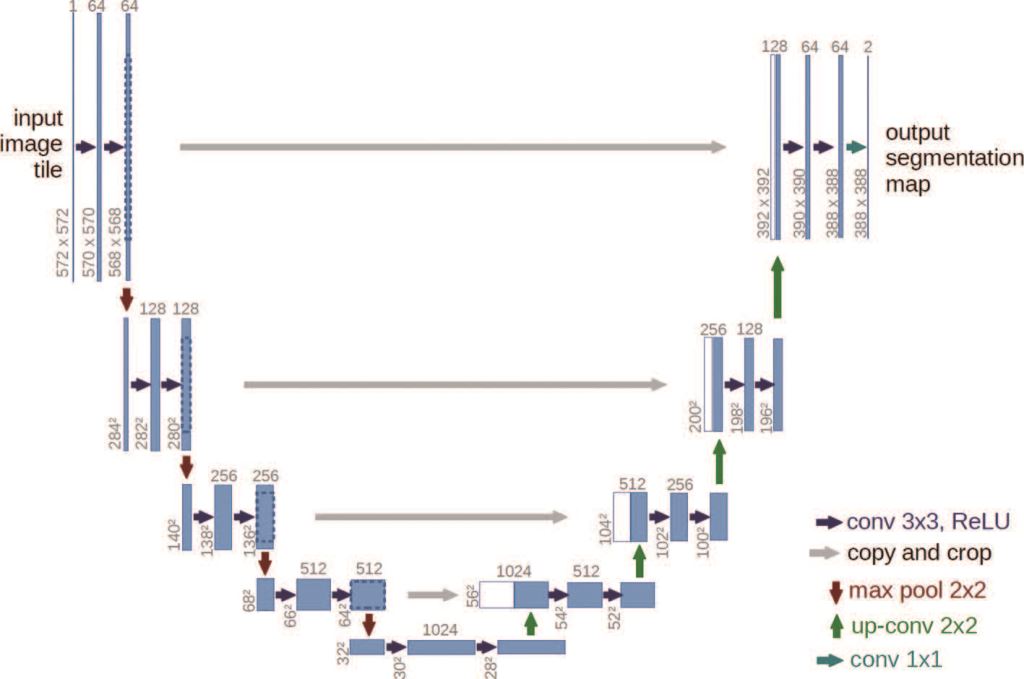
圖十、語義分割Unet架構
(4) 實例分割
實例分割技術與語義分割技術皆為像素級分類,語義分割技術是將每一個類別分類出來,當屬於相同類別時就視為同一類,所以相同類別的目標物有重疊時,則無法區分有幾個及個別之輪廓,但實例分割技術會將每一個目標物確實分割出來,相同的類別也能分割出個別輪廓及位置,即能正確的計算個數,屬於更精確的分割演算法,但相對的運算需要更久的時間,實例分割技術常應用於手臂Pick and Place,有名且經典的演算法為2017年的Mask RCNN[註8]如圖十一所示,至今許多新的實例分割演算法皆是已此架構進行延伸優化。
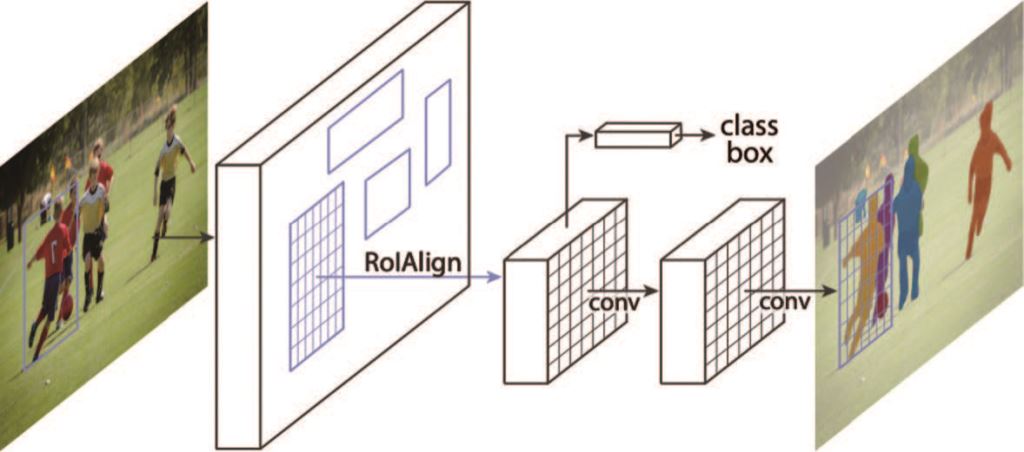
圖十一、實例分割Mask RCNN架構
▋ 案例分享
- (1) 產業類別:塑膠瓶罐業。
應用內容:瑕疵檢測如圖十二所示。
分類類別:雜點、刮傷、其他。
應用技術:物件偵測。
導入效益:解決傳統視覺多色、多型態產品需設定大量演算法參數之問題,透過一支卷積神經網路模型適用所有瓶罐。

圖十二、塑膠瓶罐業瑕疵檢測案例
- (2) 產業類別:木工機械業。
應用內容:瑕疵檢測如圖十三所示。
分類類別:木節、裂縫、邊界缺角、粗糙面。
應用技術:物件偵測。
導入效益:解決傳統視覺容易錯殺之問題,卷積神經網路透過學習瑕疵特徵改善錯判。

圖十三、木工機械業瑕疵檢測案例
- (3) 產業類別:車用塑膠業。
應用內容:瑕疵檢測如圖十四所示。
分類類別:流痕、凹痕、正常。
應用技術:語義分割。
導入效益:解決人工檢測無法量化瑕疵程度之問題,透過卷積神經網路量化瑕疵面積資訊與專家系統串接,讓產品發生異常能立即調優加工參數。
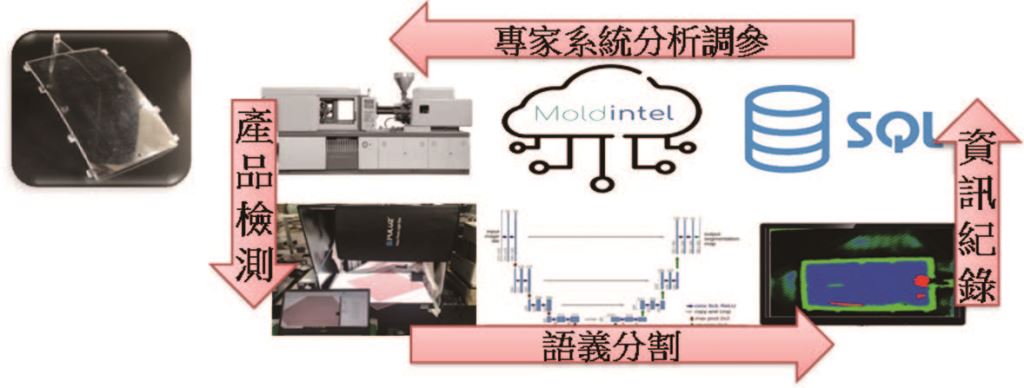
圖十四、車用塑膠業瑕疵檢測案例
- (4) 產業類別:板材業。
應用內容:瑕疵檢測如圖十五所示。
分類類別:破損、溢膠、正常。
應用技術:影像分類。
導入效益:解決人員品管跟不上生產效率之問題,以卷積神經網路讓產能提升並能夠全檢板材。
圖十五、板材業瑕疵檢測案例
▋ 結論
透過卷積神經網路實際導入至AOI,在應用上確實能夠比以往人為設計演算法來的優秀,可以解決以前視覺無法克服的問題,但也有很多需要待解決的地方,例如需要龐大資料量來驅動以找出特徵建立優良的模型及新資料學習需要連同舊資料一同訓練,不然會發生模型遺忘的問題等,因此學界、業界尚持續投入研究,希望找出更理想的卷積神經網路架構,讓建模速度、精確度能夠更為提升,引領產業導入AI AOI,加速產業轉型。
- Yann LeCun, Leon Bottou, Yoshua Bengio, Patrick Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE, pp. 2278-2324, 1998.
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition, International Conference on Learning Representations http://arxiv.org/abs/1409.1556, 2014.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778, 2016.
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, International Conference of Machine Learning, pp. 6105-6114, 2019.
- Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, You Only Look Once: Unified, Real-Time Object Detection, IEEE Conference on Computer Vision and Pattern Recognition, pp. 779-788, 2016.
- Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, arXiv preprint arXiv:2207.02696, 2022.
- Olaf Ronneberger, Philipp Fischer, Thomas Brox, U-net: Convolutional Networks for Biomedical Image Segmentation, International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 234-241, 2015.
- Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick, Mask R-CNN, IEEE International Conference on Computer Vision, pp. 2980-2988, 2017.
 |
 |